Distribution of the Grimshaw Surname in England in 1881 and 1998
(Note: Webpage in preparation)
The University College London has created a website (“Surname Profiler”) that shows the distribution of surnames in Great Britain – both current and historic – “in order to understand patterns of regional economic development, population movement and cultural identity.” This website provides the ability to search the databases that have been created and “to trace the geography and history of … family names.” Searches can be made for the years 1881 and 1998. The website can be visited at the following address:
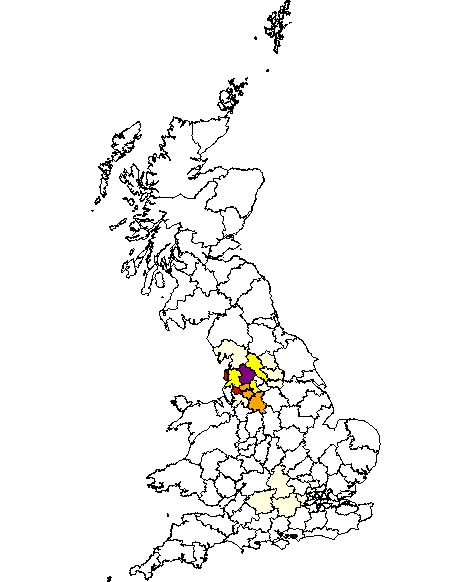
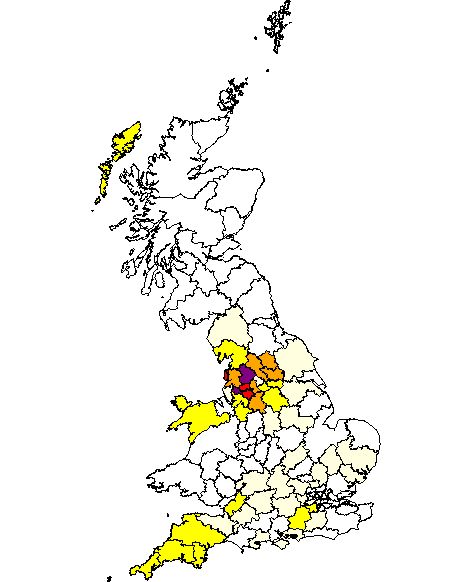
A search of the website for “Grimshaw” yielded the results shown in this webpage. A description of the website and its contents are also provided.
Contents
Search Results for Grimshaws in the 1881 Database
Search Results for Grimshaws in the 1998 Database
Webpage Credits
Thanks go to Ken Grimshaw, born in Clayton-le-Moors, but now residing in London, for providing the reference to the website that is described on this webpage.
Search Results for Grimshaws in the 1881 Database

| International Comparisons | ||
| International Comparisons | Rate | As % of GB rate in 1998 |
|
Great Britain Frequency (1998)
|
4974
|
100
|
|
Great Britain Frequency (1881)
|
4992
|
|
|
Great Britain Rate (1998)
|
125
|
|
|
Great Britain Rate (1881)
|
185
|
|
|
Northern Ireland
|
27.39
|
22.2
|
|
Republic of Ireland
|
0.00
|
0.0
|
|
Australia
|
74.77
|
60.5
|
|
New Zealand
|
39.40
|
31.9
|
|
United States
|
15.77
|
12.8
|
|
Canada
|
30.94
|
25.0
|
Search Results for Grimshaws in the 1998 Database
International Comparisons | ||
| International Comparisons | Rate | As % of GB rate in 1998 |
|
Great Britain Frequency (1998)
|
4974
|
100
|
|
Great Britain Frequency (1881)
|
4992
|
|
|
Great Britain Rate (1998)
|
125
|
|
|
Great Britain Rate (1881)
|
185
|
|
|
Northern Ireland
|
27.39
|
22.2
|
|
Republic of Ireland
|
0.00
|
0.0
|
|
Australia
|
74.77
|
60.5
|
|
New Zealand
|
39.40
|
31.9
|
|
United States
|
15.77
|
12.8
|
|
Canada
|
30.94
|
25.0
|
Surname Profiler Website Description

Welcome to the Surname Profiler Project Website
A recent research project based at University College London (UCL) has investigated the distribution of surnames in Great Britain, both current and historic, in order to understand patterns of regional economic development, population movement and cultural identity. This website allows users to search the databases that we have created, and to trace the geography and history of their family names.
On each page of the website, you will find a Help link on the top-right corner. This will hopefully answer any questions you have about the data, maps and statistics. This provides a full explanation of how statistics are derived, and how best to understand the map. For your best understanding, please do make full use of this facility.
Data Sources:
UK and Ireland data: Experian International Ltd US data: Dr. D. Kenneth Tucker, Carleton University, Ottawa, Canada Australia data: Pacific Micromarketing Pty New Zealand data: Circular Distributors Great Britain Census of 1881: Economic and Social Research Council Data Archive
Acknowledgements:
Thanks to the following for their contributions: The Economic and Social Research Council for funding our research project on Surnames as a quantitative evidence resource for the social sciences (grant reference RES-000-22-0400) Circular Distributors, Experian, Pacific Micromarketing, Dr D. Ken Tucker, Professor Kevin Schürer for the supply of data and advice.
Project Acknowledgements:
Professor Paul Longley : Project development
Professor Richard Webber : Project co-ordinator and content
Dr Daryl Lloyd : Co-data manager
Alex Singleton : Co-data manager & website managerIf you wish to provide any feedback, comments, or
corrections, please email us.Going Further:
Click here to see references and related papers
Version 1.3 (installed 3rd January, 2006)
Last minor update: 12th February, 2006Recent changes (most recent at top) –
We have added maps of groups of surnames. If you search using the “Category of names” option and then select the overall category highlighted in green at the top, a map for all the surname in that category will be produced. There are no statistics for these yet, but they should be added very soon. (12/2/2006) Many new online reviews and reports have been referenced. Please go to www.spatial-literacy.org. (2/2/2006) Added reference to the article in The Observer. (15/1/2006) (on references
page) Corrected the errors on some of the names for the 1881 frequencies. Updated help files on Experian’s Mosaic classification.How are names classified?
This help page provides information regarding the name classification used for this project. It details the rules that were used for assigning names to categories which are based on an explicit hierarchy of precedents. You can read further about the rule that takes precedence over all other rules which is the origin of the name, i.e. Celtic, English or Imported origin.
The Name ClassificationThe names database contains information on the size and geographical distribution of 25,630 family names.
To qualify for inclusion in this list there must have been at least one hundred entries under that family name in the Great Britain electoral register for 1996.
A key feature of the database is that every family name has been given a detailed classification code explaining what type of name it is.
Most people will be familiar with the major groupings into which names can be classified. The term toponym, for example, is used to indicate the geographical location from which a persons name is likely to have originated. Names such as Kendal and Darbyshire are example of this class of name.
Likewise the term patronym is used to describe family names which were originally assigned to people on account of the personal name of their father or mother. The names Jones and Robinson would fall into this general class.
Metonyms are another important class of name. These originated from the names of the trades or occupations from which people earned their living. Persons with the names Smith or Wright have names that belong to this class.
Another important class of names are nicknames. Some of these, such as Strong or Blunt, might have been used to describe the physique or personality of a person. It is thought that other nicknames, such as Pope and King, describe roles that people may have played at carnival time.
Such classes of name are clearly of interest if we are to understand the meanings that different family names represent. But it can also be interesting to examine the size and geography of different classes of name.
Taking the class of names that supposedly take their names from counties, it is notable that the names Kent, Darbyshire and Wiltshire are far more common than names taken from equally well known counties, such as Suffolk, Nottinghamshire or Somerset.
Very often different forms of name are revealing of naming practices in different regions of the country. When we map the geographical distribution of people with patronymic names ending in-son we find highest concentrations along the North Sea coast, from the Humber to the Shetlands. Patronymic names ending in -s, by contrast, are more common in South Wales and the West of England. Patronyms starting with the prefix Ap- are more common in mid-Wales than in either south or north Wales.
To help people better understand the characteristics of individual family names we have arranged each name into one of 225 categories, based in part on the meaning of the name but also on its form, on its origins and on its historic and current geographical concentrations.
The categories are organised hierarchically. So the name Hodgkinson would belong to the general class of patronymic names. Within that class it would belong to the sub-group names ending in -son. Within that sub-group it would belong to a set of names which ended in -kinson. Other names in the same category would be Watkinson, Dickinson, Parkinson, Tomlinson and Sinkinson. Strictly the name Tomlinson may end in linson rather than -kinson but all five, along with Hodgkinson, are structured in a similar way, being the son of little Roger, Walter, Richard, Peter, Thomas and Simon respectively.
To cater for the variety of non English surnames now found on Britains electoral registers, we have also had to incorporate culture, ethnicity and language into the classification system, reserving two major classes for Celtic names and for those Imported from abroad. Within these classes we can in certain instances further divide names on the basis of their meaning, as for example grouping names starting with Mac- or Fitz-. More commonly however our Celtic and Imported name classes are further sub divided on the basis of the cultures and countries from which the surnames originated.
For example within the general class of Imported names we can distinguish a sub group which originates from Black Africa and, from within that, further more detailed categories of names which originate from Ghana and from Nigeria.
Some 8% of the names on our database are too individual or obscure to fit within any of these categories. In addition to these there are some names which may have more than one origin. The name Gill for example is common both among Sikhs and in Cumbria, in which county it represents the local name for a stream.
The following section sets out the logic whereby we decide the most appropriate category for each name in such situations of potential conflict.
Rules for assigning names to categories
There are many names in the database which could be assigned to more than one category. The name Lloyd, which in Wales means grey, could be grouped along with Vaughan (the Welsh for red), Black, White, Green and Rose as names belonging to the category Colours. The name Lloyd could also be classified as a Welsh name within the class Celtic. Due to its very high concentration in postal areas LD and SY the name would also qualify to be considered as belonging to a sub group of regional names.
Clearly it is necessary to spell out the rules used to put names into a category in situations of potential conflict such as this.
These rules are based on an explicit hierarchy of precedents. The rule that takes precedence over all other rules is whether or not a name is of Celtic, English or Imported origin.
This decision is made using a large number of different criteria. One of the more important of these is whether people with that family name tend disproportionately to have been given first names which are traditionally associated with a particular cultural group. For example whilst very few people called Parker have first names which are not English, many people called Prosser have names such as Rhiannon and Dafydd which suggests that the name is of Welsh origin.
Examining the change in relative frequencies of the name in 1881 and 1996, the postal areas where the name was prevalent in 1881 and 1996 and whether the name is more or less common in the US and in Australia are other useful indications of whether a name is English or not.
English Names
If a name is best classified as English, it is then assigned to a sub group on the basis of the meaning of the name. For example all names ending in -kin or -ett will be grouped together into the sub group diminutives which names such as Eagle and Crane will be grouped together in the category bird names.
If a name falls into none of the available sub groups on the basis of its meaning we next test the extent to which its members are particularly concentrated in certain areas of the country. The rules governing whether or not an otherwise unclassified name is considered Regional are fairly complex. For more common names we look to see whether the concentration of the name in the postal area where it has the highest concentration exceeds a certain threshold rate. Less common names are tested to see whether the postal area in which they were most concentrated in 1881 is also the one where they are most concentrated in 1998. A name can also be classified as regional if the two postal areas where the name was most concentrated in 1881 were contiguous with each other.
Names which qualify to be considered as Regional are then further categorised according to the standard administrative regions into which the country is divided.
If an English name fails all of these tests, then it is assigned to an Unclassified category.
Celtic Names
Within the Celtic group we separately split out Irish, Scottish, Welsh and Cornish family names. The majority of Celtic names are assigned to their country on the basis of the linguistic structure. Thus we have a category for Cornish names which start with habitational elements, such as Tre-, Pol- and Pen-. Names starting with Fitz- belong to a category within the Irish sub group and names starting with Ap-, the Welsh for son of, are grouped together into a Welsh sub group. These linguistic rules are applied whether or not the name is now more common in Ireland, Scotland, Wales or Cornwall than elsewhere in Britain.
By comparing the numbers of occurrences per million names in the Republic of Ireland, Northern Ireland and Scotland, we can also differentiate names, such as those starting with Mc- or Mac- according to which of the three cultural regions they are most common in.
We also treat as Celtic other names which have levels of concentration in Scotland or Wales sufficient for them to qualify as Regional names. These names may not look or sound Scottish or Welsh but it is evident from their geographical distribution that these are the countries where they originated.
Names which are Celtic in terms of language structure or can be inferred as being Celtic from their fist names but which do not fit into any of the Celtic categories will be categorised as Irish – Other, Scottish- Other and so on.
Names imported from abroad
The third major grouping is described as Imported from abroad. Within this group it is possible to separately analyse a number of key cultural ethnic and linguistic groups. For example we separately identify names that originate from East Asia, from South Asia, from the Muslim World, from Black Africa, from a Hispanic culture and from non Hispanic Europe. We have a further sub group consisting of Jewish names.
The division of names Imported from abroad takes into account culture (or religion), ethnicity and language. For example names from the Spanish and Portugese languages are common not just in Europe but also in Latin America and even the Philippines. Muslim names are common from North Africa to Indonesia and some East Asian names are quite common in parts of the Caribbean. The division between Muslim North Africa and Black Africa is imprecise since many immigrants to Britain from the mainly Muslim north of Nigeria and Ghana have Muslim names, whilst Shah is popular in Uganda and Muslim names uncommon in Ethiopia.
In South Asia likewise it is difficult to draw the precise dividing line between Muslim, Sikh and Pakistani names, with Pakistanis and Bangladeshis being included in the Muslim rather than in the South Asian sub group.
Within most of these sub groups it is then possible to further refine the classification at country level, for example by distinguishing Danish from Swedish names, Polish from Hungarian names and Turkish from North African names.
In addition to assigning each name to an individual classification, we also provide information, where applicable, where a name is associated with two or more different cultural, ethnic and linguistic categories.

Webpage History
Webpage posted February 2006. Banner replaced April 2011.